
Information required by practicing architects, engineers, construction managers, building operators, asset managers, owners, and users becomes more and more distributed, detailed, and richer. BIG DATA is on the rise and this trend will not stop. We rather expect that this trend will further accelerate in the upcoming years as;
• more and more sensor technologies will become widely available to access existing conditions in the built environment,
• more and more information streams will be combined for various purposes, e.g. mobile data access information to space use in order to evaluate wireless infrastructure performance but also to establish building use patterns in post-occupancy evaluations,
• advanced design tools will allow for more detailed data-driven simulation of an increasing number of design alternatives in shorter time spans, and
• participatory efforts will involve an ever larger number of specialists and non-specialists that all provide information that needs to be accounted for during design and construction planning.

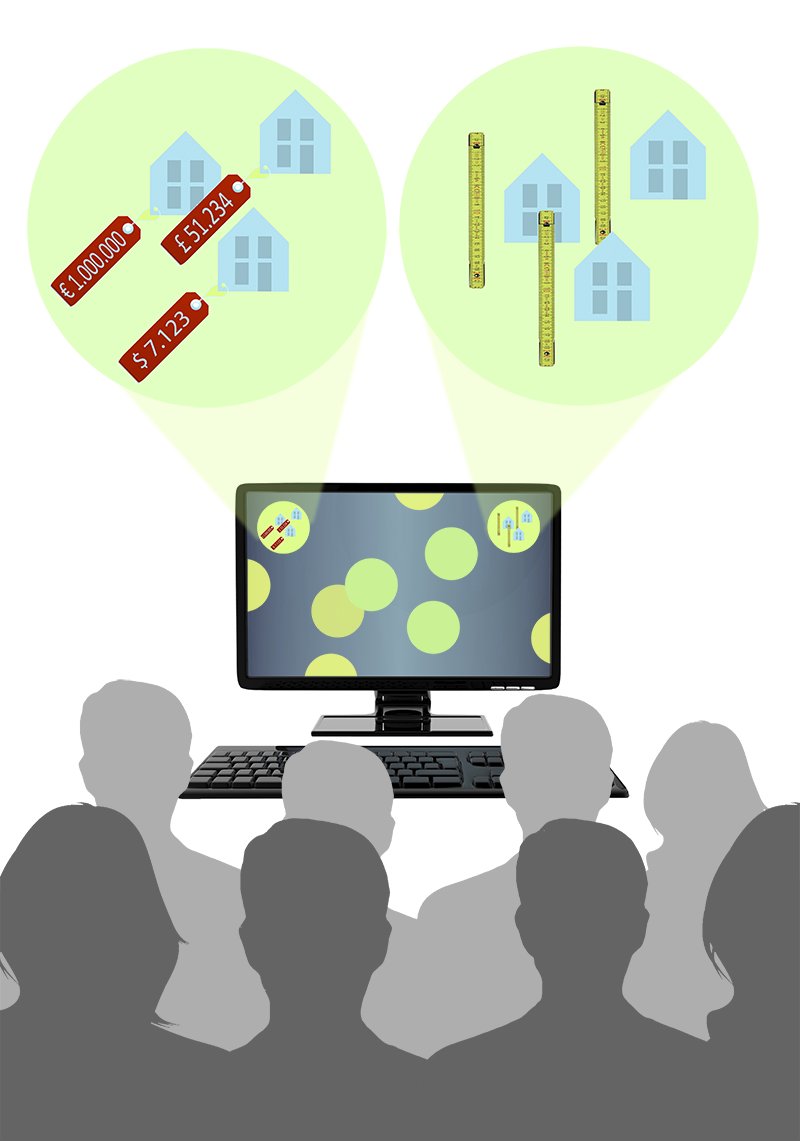
Humans will no longer be able to ensure the consistency of information and, more importantly, find the - for them - relevant data.
The availability of the above described BIG DATA will mean that data sources in the future will be based upon an increasing amount of standards, information models, and semantic dictionaries. Additionally, data sources will become increasingly distributed across the web. Practitioners need to be supported in finding, combining, and acting on this distributed information. Already posing a problem for engineering practice today, in this changing world, humans will no longer be able to ensure the consistency of information and, more importantly, find the for them relevant information.
To this end, semantic web technologies are required that allow machines to readily interpret information and can perform much of the tedious and time consuming work involved in working with distributed BIG DATA repositories. After all, computers can support humans in indexing and searching data. We expect that this will be one of the most important and prominent areas for research in the upcoming years. In this lighthouse project we made a number of first important steps to enable such research.

3TU BIM Data Repository
We set up a repository structure for storing building related information within an archive. This archive will allow us to collect all data that students at the 3TUs developed in the last years and will develop in the years to come. In collaboration with the FP7 EU project ‘DURAARK’, a repository for the sustainable long term preservation of digital building information in different formats, including the Open Industry Foundation Classes (IFC) has been created and will be filled over time. The repository, made available in the Amazon cloud by project partner Microsoft, can then be used by researchers to develop indexing and search solutions and to empirically test them. We also expect that the repository can grow into a benchmark for testing developed indexing and search algorithms with respect to their performance in terms of speed, completeness, and stability.
Data format, standard, and dictionary map
We also made a first start for establishing a map of the available data formats, standards, and dictionaries to describe building related data. The map will provide an overview of the ontological spectrum within the field of civil engineering. The spectrum, in turn, will allow researchers to start developing different translation mechanisms between the different existing data formats, standards, and dictionaries to arrive at homogeneous indexing and search solutions in the long term.
Information use and exchange processes
A start was made to understand and develop future information use and exchange processes that assume a widely distributed information environment. This part of the research is important to provide the basis for developing practically applicable indexing and search workflows.
Automated indexing methods
A first step was made into exploring possibilities for automatically indexing the semantic information available within the large amount of existing data formats, standards, and dictionaries. Based on a selected number of case projects, first indexes have been extracted and explored according to their utility to support engineering work.
The above summarized four steps, even within the quite early stage of development they are in, provide a strong foundation for semantic web research at the 3TU in the years to come. The steps provide a platform and an initial research framework for academic research at the Bachelor, Master, and PhD level.

Project Team
University of Twente
dr. Timo Hartmann
prof. dr. ir. Arjen Adriaanse
Eindhoven University of Technology
dr. Dipl.-Ing Jakob Beetz
ir. Thomas Krijnen
Delft University of Technology
dr. ir. Alexander Koutamanis
Balast Nedam
Microsoft Netherlands